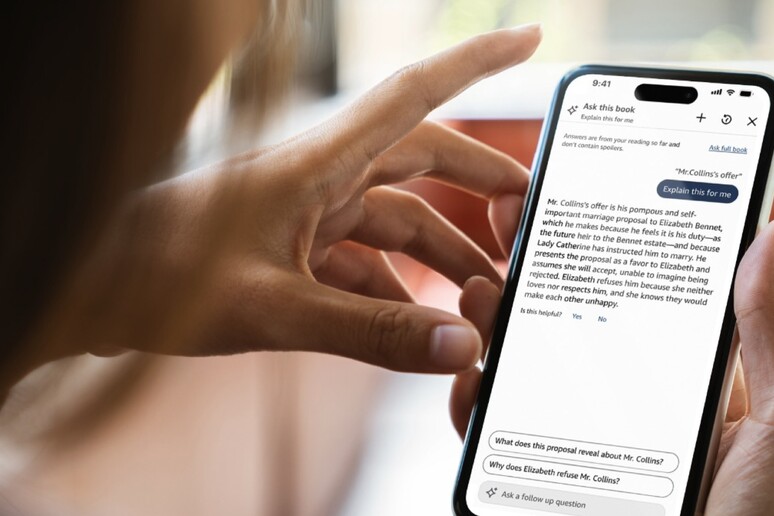
Il colosso dell’e-commerce Amazon ha introdotto una novità destinata a modificare l’esperienza di lettura digitale: “Chiedi a questo libro” (“Ask this Book”). Si tratta di una funzionalità basata sull’intelligenza artificiale, attualmente disponibile per migliaia di ebook in lingua inglese sull’app Kindle per iOS negli Stati Uniti, che promette di rendere la lettura più immersiva e interattiva. Tuttavia, dietro l’innovazione si celano ombre che hanno già iniziato a sollevare un polverone nel mondo editoriale, riaccendendo il complesso dibattito sul rapporto tra tecnologia e diritto d’autore.
Un assistente di lettura personale e senza spoiler
L’idea alla base di “Chiedi a questo libro” è semplice quanto ambiziosa: fornire ai lettori un assistente virtuale in grado di rispondere a domande specifiche sull’opera che stanno leggendo. Quante volte, immersi in un romanzo complesso, ci si è trovati a non ricordare il nome di un personaggio secondario o un dettaglio cruciale della trama? La nuova funzione di Amazon interviene proprio in questi frangenti. Evidenziando una parola o una frase, l’utente può interrogare il sistema, digitando la propria domanda o scegliendo tra quelle suggerite, e ricevere risposte immediate e contestualizzate.
La caratteristica più apprezzata, e sulla quale Amazon ha posto grande enfasi, è la garanzia “spoiler-free”. L’intelligenza artificiale, infatti, analizza l’intero testo ma fornisce risposte basate esclusivamente sui contenuti letti fino a quel momento dall’utente. In questo modo, è possibile rinfrescare la memoria senza il rischio di incappare in anticipazioni indesiderate, un pericolo sempre presente nelle ricerche online su forum o siti web. L’obiettivo dichiarato da Amazon è quello di “rendere più semplice rimanere immersi nei propri libri”, evitando interruzioni e mantenendo il flusso della lettura.
Il nodo del contendere: l’impossibilità di “opt-out”
Se da un lato la funzione si presenta come un utile strumento per i lettori, dall’altro ha scatenato immediate e accese polemiche da parte di autori ed editori. Il punto cruciale della controversia risiede in una decisione unilaterale di Amazon: la funzione è “sempre attiva” e non è prevista alcuna possibilità di “opt-out”. Questo significa che autori ed editori non possono scegliere di escludere le proprie opere dal servizio. Il sistema di Amazon, di fatto, ha accesso ai libri e li elabora senza richiedere un’autorizzazione esplicita ai detentori dei diritti.
Questa imposizione ha sollevato un vespaio di critiche, incentrate sulla violazione del copyright e sulla perdita di controllo da parte dei creatori sui propri contenuti. In un’intervista alla rivista di settore PubLunch, un portavoce di Amazon ha giustificato la scelta con la necessità di “garantire un’esperienza di lettura coerente”. Tuttavia, la società non ha fornito dettagli chiari sulle licenze utilizzate per abilitare lo strumento né sulle protezioni tecniche adottate, lasciando irrisolte questioni fondamentali.
Le preoccupazioni sono molteplici e fondate:
- Utilizzo non autorizzato: L’analisi dei testi da parte dell’IA viene vista da molti come un utilizzo non autorizzato di materiale protetto da copyright, simile a quello contestato nell’addestramento dei grandi modelli linguistici (LLM).
- Mancanza di compenso: Gli autori non ricevono alcun compenso per questo utilizzo delle loro opere, che di fatto contribuisce a migliorare un servizio di Amazon.
- Rischio di “allucinazioni”: Non è chiaro come Amazon intenda prevenire le cosiddette “allucinazioni” dell’IA, ovvero la generazione di informazioni errate o fuorvianti sul contenuto del libro.
- Precedente pericoloso: La decisione di Amazon potrebbe creare un precedente, spingendo altre piattaforme a utilizzare contenuti protetti senza il consenso dei creatori.
Un contesto legale e tecnologico in piena ebollizione
La vicenda di “Chiedi a questo libro” si inserisce in un contesto globale di grande tensione legale sull’uso dell’intelligenza artificiale. Diverse grandi aziende tecnologiche stanno affrontando cause legali per aver utilizzato contenuti protetti da copyright per addestrare i propri modelli linguistici. Esempi noti sono le azioni legali intentate da testate come il New York Times e il Chicago Tribune contro la piattaforma Perplexity per presunte violazioni.
In Europa, la Federazione degli Editori Europei ha invocato il rispetto delle regole previste dalla Direttiva Copyright del 2019, che consente l’estrazione di testi e dati solo se non espressamente vietata dai titolari dei diritti. La questione è complessa e tocca il cuore del diritto d’autore: fino a che punto una macchina può “leggere” e “imparare” da un’opera protetta senza violarne la proprietà intellettuale?
Inoltre, l’affidabilità di questi strumenti è ancora tutta da dimostrare. Amazon stessa ha dovuto recentemente ritirare una funzione di riassunti video generati da IA per la sua piattaforma Prime Video, a causa di significative imprecisioni emerse. Questo solleva dubbi anche sull’accuratezza delle risposte che “Chiedi a questo libro” potrà fornire.
Prospettive future: tra espansione e battaglie legali
Nonostante le polemiche, Amazon sembra intenzionata a proseguire su questa strada. L’azienda ha già annunciato che la funzione “Chiedi a questo libro” verrà estesa nel 2026 anche ai dispositivi Kindle e all’app per Android. Inoltre, è in arrivo un’altra funzione basata su IA, chiamata “Recaps”, che genererà riassunti dei volumi precedenti all’interno di una saga letteraria.
Mentre i lettori attendono di poter sperimentare queste nuove frontiere dell’interattività, il mondo editoriale si prepara a una probabile battaglia legale. La mossa di Amazon potrebbe rappresentare un punto di non ritorno, costringendo l’industria a ridefinire i confini del diritto d’autore nell’era dell’intelligenza artificiale generativa. La domanda che resta sospesa è se l’innovazione tecnologica possa procedere ignorando i diritti e il consenso di chi, con la propria creatività, fornisce la materia prima essenziale: le storie.